Vision-based reinforcement learning for lane-tracking control
What is Vision-based Reinforcement Learning? A few important topics:
Reinforcement Learning: a machine learning paradigm where an agent learns to make decisions by interacting with an environment to achieve a goal. In this context, reinforcement learning is used to teach a vehicle how to drive within Duckietown lanes by providing rewards or penalties based on its actions.
Vision-based Control: The control of the vehicle is based on visual inputs, specifically images captured by a forward-facing camera. These images are processed by a neural network to determine appropriate steering actions, allowing the vehicle to track lanes and avoid collisions.
Simulation-to-Reality (sim2real) Transfer Learning: The trained policy, which learns to control the vehicle in a simulated environment, is transferred to real-world scenarios. The effectiveness of the trained model in real-world driving situations is evaluated, demonstrating the ability to generalize learning from simulation to reality.
Domain Randomization: This technique involves introducing variations or randomizations into the simulation environment during training. By exposing the agent to a wide range of simulated scenarios with different lighting conditions, road surfaces, and other environmental factors, domain randomization helps improve the model’s ability to generalize to unseen real-world conditions.
Learn about RL, navigation and other robot autonomy topics at the link below!
The present study focused on vision-based end-to-end reinforcement learning in relation to vehicle control problems such as lane following and collision avoidance. The controller policy presented in this paper is able to control a small-scale robot to follow the right-hand lane of a real two-lane road, although its training has only been carried out in a simulation.
This model, realised by a simple, convolutional network, relies on images of a forward-facing monocular camera and generates continuous actions that directly control the vehicle. To train this policy, proximal policy optimization was used, and to achieve the generalisation capability required for real performance, domain randomisation was used. A thorough analysis of the trained policy was conducted by measuring multiple performance metrics and comparing these to baselines that rely on other methods.
To assess the quality of the simulation-to-reality transfer learning process and the performance of the controller in the real world, simple metrics were measured on a real track and compared with results from a matching simulation. Further analysis was carried out by visualising salient object maps.
Highlights - Vision-based reinforcement learning for lane-tracking control
Here is a visual tour of the work of the authors. For more details, check out the full paper.
Fig 1. Illustration of the policy architecture with the notations used.
Fig 2. Explanation of the proposed orientation reward
Fig 3. Examples of domain randomised observations
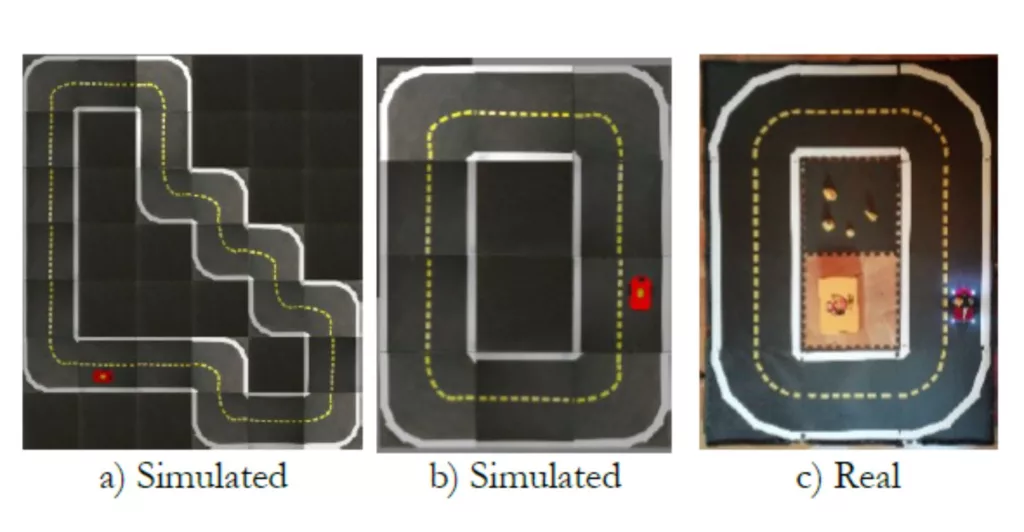
Fig 4. .a) Test track used for simulated reinforcement learning and baseline evaluations; b) and c) real and simulated test track used for the evaluation of the simulation-to-reality transfer.
Fig 5. Learning curves for the reinforcement learning agent with different action representations and reward functions.
Fig 6. Sequence of Robot Positions in Collision Avoidance Experiment with Modified Orientation Reward Trained Policy
Fig 7. Salient objects highlighted on observations in different domains and tasks. Blue regions represent high activations throughout the network.
Conclusion
Here are the conclusions from the authors of this paper:
“This work presented a solution to the problem of complex, vision-based lane following in the Duckietown environment using reinforcement learning to train an end-to-end steering policy capable of simulation-to-real transfer learning. It was found that the training is sensitive to problem formulation, such as the representation of actions.
This study has demonstrated that by using domain randomisation, a moderately detailed and accurate simulation is sufficient for training end-to-end lane-following agents that operate in a real environment. The performance of these agents was evaluated by comparing some basic metrics to match real and simulated scenarios.
Agents were also successfully trained to perform collision avoidance in addition to lane following. Finally, salient object visualisation was used to give an illustrative explanation of the inner workings of the policies in both the real and simulated domains.”.
Duckietown is a platform for creating and disseminating robotics and AI learning experiences.
It is modular, customizable and state-of-the-art, and designed to teach, learn, and do research. From exploring the fundamentals of computer science and automation to pushing the boundaries of knowledge, Duckietown evolves with the skills of the user.
End-to-end Deep RL (DRL) systems: in autonomous driving environments that rely on visual input for vehicle control face potential security risks, including:
State Adversarial Perturbations: Subtle alterations to visual input that mislead the DRL agent, causing incorrect decision-making.
Reward Tampering: Manipulation of the reward signal to misguide the learning process, leading the agent to adopt unsafe or inefficient policies.
These vulnerabilities can compromise the safety and reliability of self-driving vehicles.