






Lecturer Vikram Radhakrishnan shares how he is teaching robot autonomy at The Hague University through hands-on robotics, computer vision, SLAM, and real-world student projects.

Learn more about the Rome Cup 2026, organized since 2007 by the Fondazione Mondo Digitale in Rome. Dedicated to students, businesses and institutions.

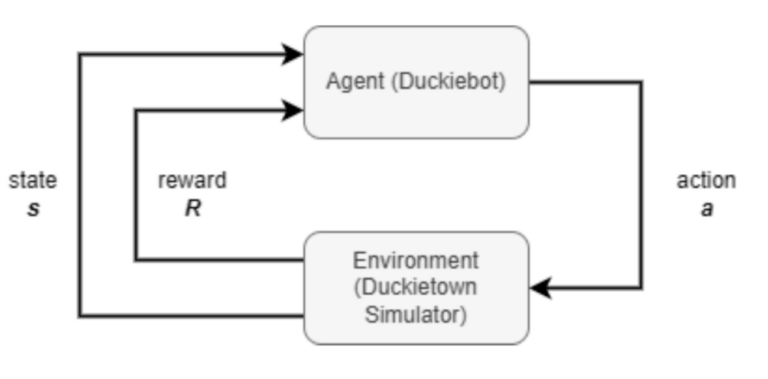
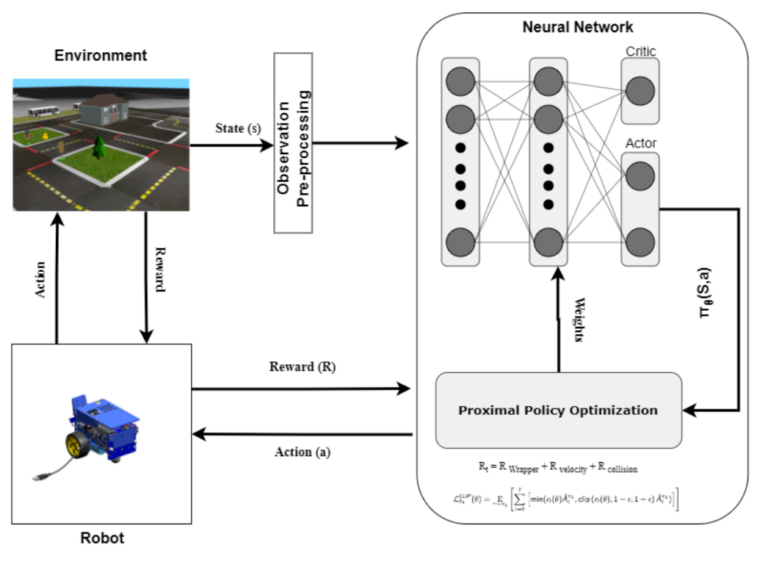
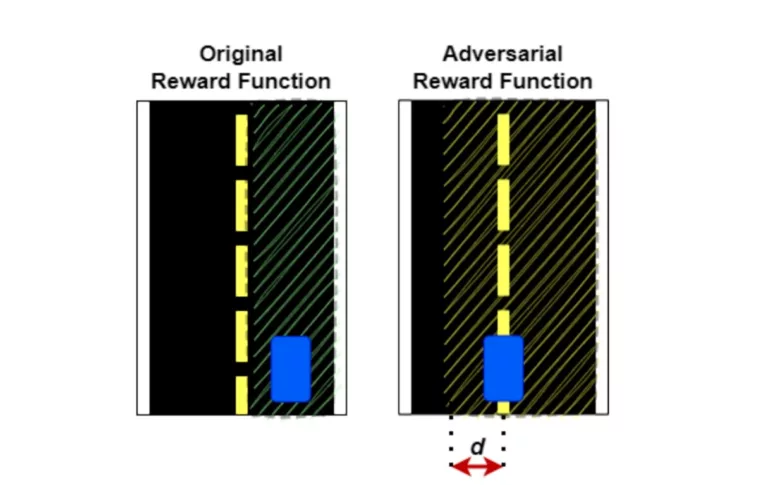
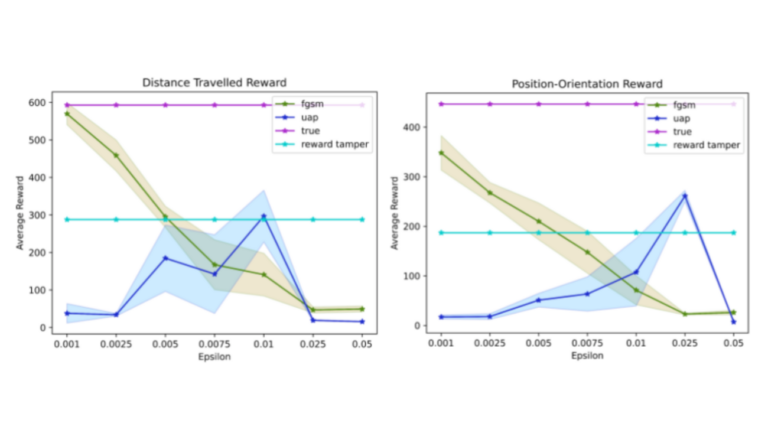
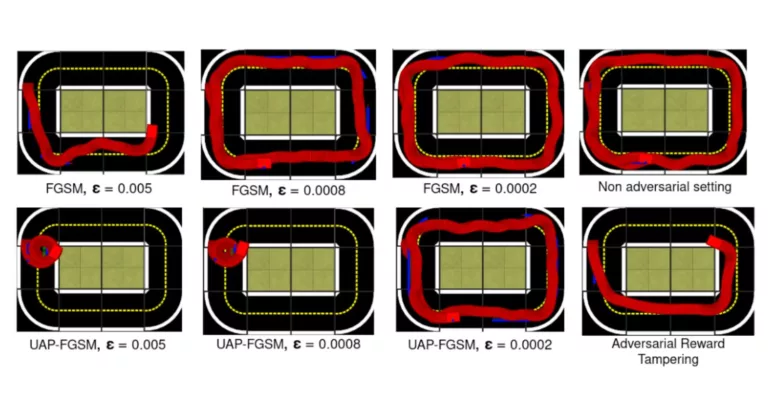
This project explores Reinforcement Learning in Duckiematrix within Duckietown, analyzing real-time delays and their impact on autonomous driving performance.