
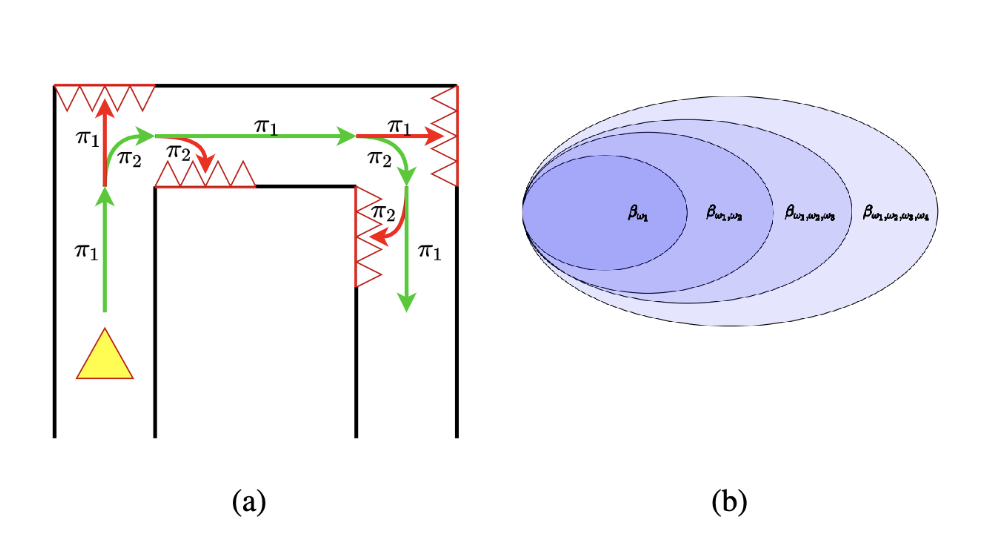

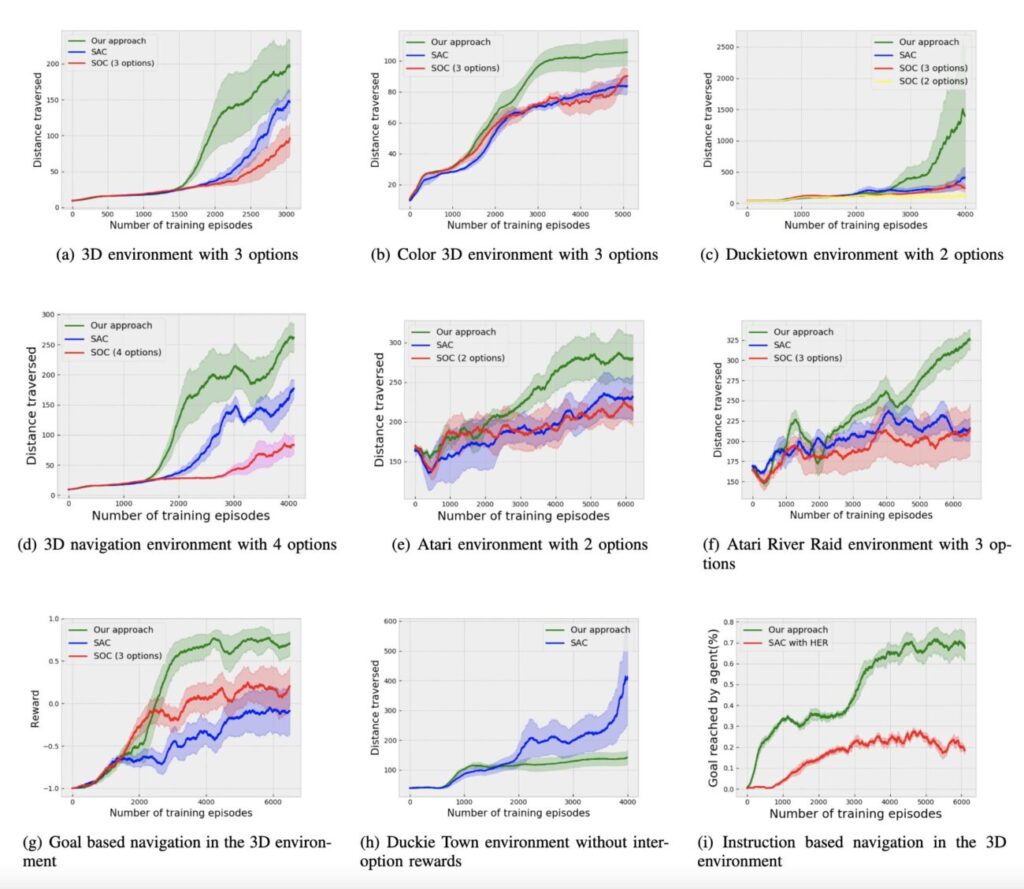
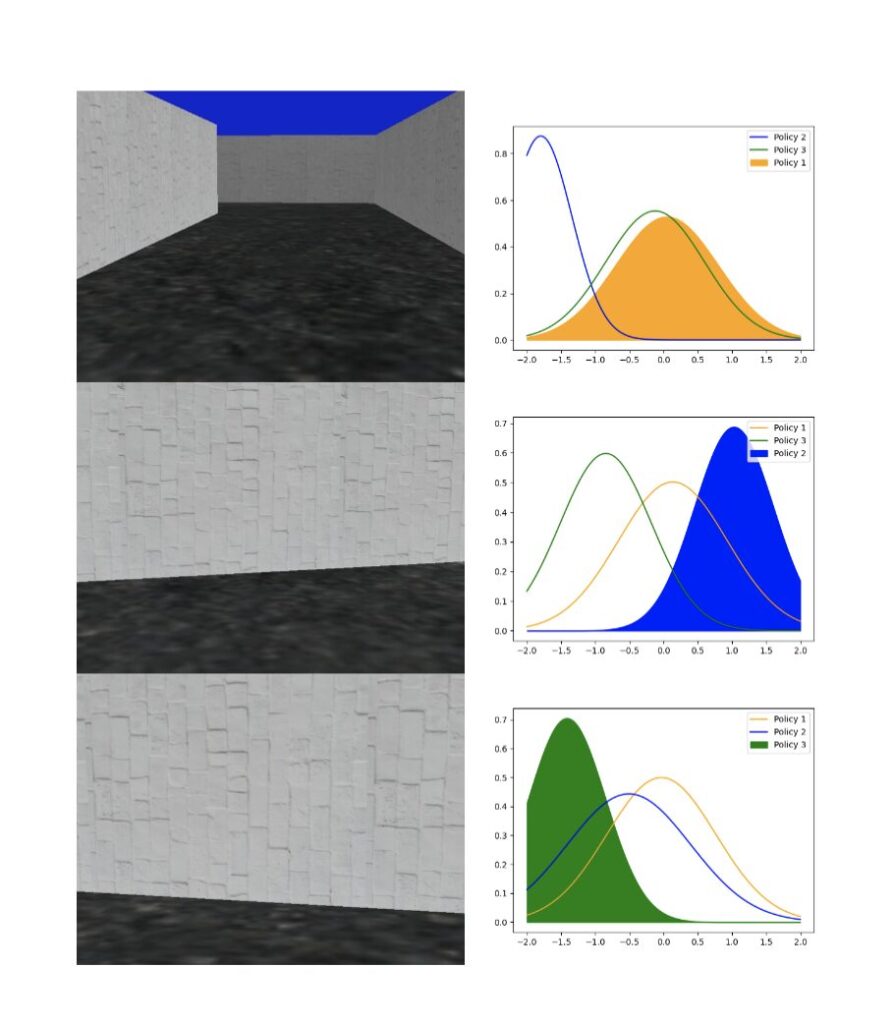


This project explores Reinforcement Learning in Duckiematrix within Duckietown, analyzing real-time delays and their impact on autonomous driving performance.

The DB21Jv3 Duckiebot upgrade kit improves the omnidirectional wheel, reduces assembly time and increases compatibility with a range of Jetson Nano kits.

Save time and start using your robot right out of the box with pre-assembled and pre-initialized Duckiebots, now available on the Duckietown shop.