
General Information
- A Survey on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms
- Armin Mokhtarian, Jianye Xu, Patrick Scheffe, Maximilian Kloock, Simon Schäfer, Heeseung Bang, Viet-Anh Le, Sangeet Ulhas, Johannes Betz, Sean Wilson, Spring Berman, Liam Paull, Amanda Prorok, Bassam Alrifaee
- RWTH Aachen University, Germany
- Mokhtarian, Armin & Scheffe, Patrick & Kloock, Maximilian & Schäfer, Simon & Bang, Heeseung & Le, Viet-Anh & Sankaramangalam Ulhas, Sangeet & Betz, Johannes & Wilson, Sean & Berman, Spring & Prorok, Amanda & Alrifaee, Bassam. (2024). A Survey on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms. 10.13140/RG.2.2.16176.74248/1.
Survey on Testbeds for Vehicle Autonomy & Robot Swarms

“A Survey on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms“ by Armin Mokhtarian et al. offers a comparison of current small-scale testbeds for Connected and Automated Vehicles (CAVs), Vehicle Autonomy and Robot Swarms (RS).
As mentioned in , small-scale autonomous vehicle testbeds are paving the way to faster and more meaningful research and development in vehicle autonomy, embodied AI, and AI robotics as a whole.
Although small-scale, often made of off-the-shelf components and relatively low-cost, these platforms provide the opportunity for deep insights into specific scientific and technological challenges of autonomy.
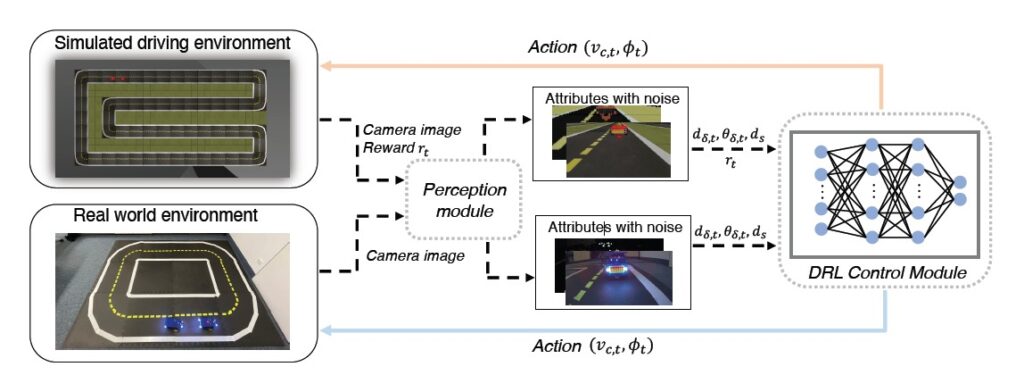
Duckietown, in particular, is highlighted for its modular, miniature-scale smart-city environment, which facilitates the study of autonomous vehicle localization and traffic management through onboard sensors.
Learn about robot autonomy, traditional robotics autonomy architectures, agent training, sim2real, navigation, and other topics with Duckietown, starting from the link below!
Abstract
Connected and Automated Vehicles (CAVs) and Robot Swarms (RS) have the potential to transform the transportation and manufacturing sectors into safer, more efficient, sustainable systems.
However, extensive testing and validation of their algorithms are required. Small-scale testbeds offer a cost-effective and controlled environment for testing algorithms, bridging the gap between full-scale experiments and simulations. This paper provides a structured overview of characteristics of testbeds based on the sense-plan-act paradigm, enabling the classification of existing testbeds.
Its aim is to present a comprehensive survey of various testbeds and their capabilities. We investigated 17 testbeds and present our results on the public webpage https://cpm.lrt.unibw.de/survey/.
Furthermore, this paper examines seven testbeds in detail to demonstrate how the identified characteristics can be used for classification purposes.
Highlights - Survey on Testbeds for Vehicle Autonomy & Robot Swarms
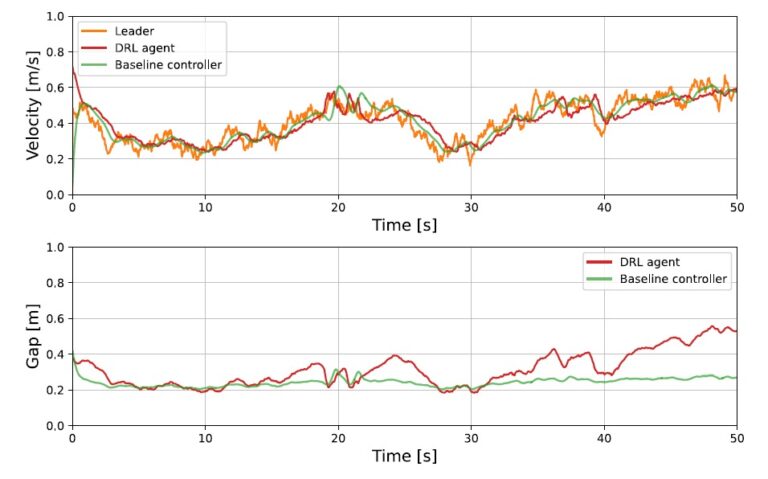
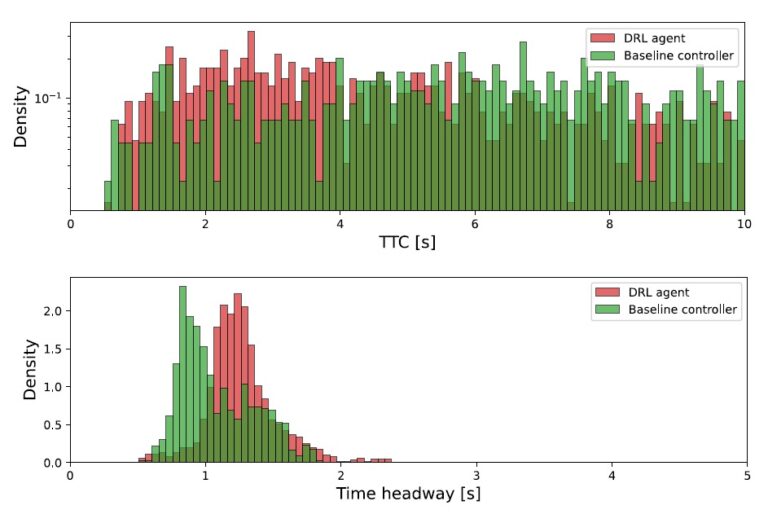
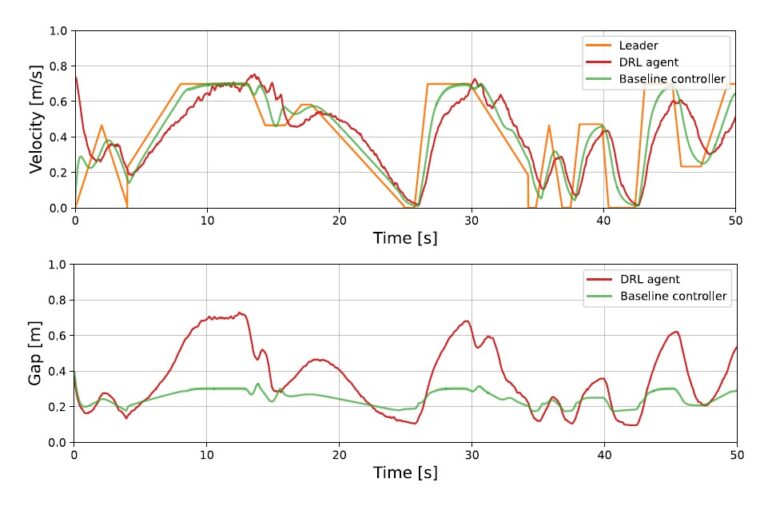
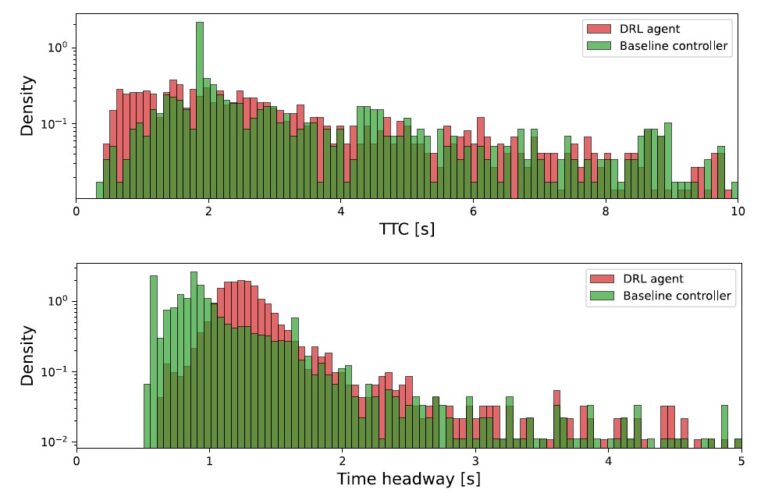
Here is a visual tour of the authors’ work. For more details, check out the full paper or the corresponding up-to-date project website.

Conclusion - Survey on Testbeds for Vehicle Autonomy & Robot Swarms
Here are the conclusions from the authors of this paper:
“This survey provides a detailed overview of small-scale CAV/RS testbeds, with the aim of helping researchers in these fields to select or build the most suitable testbed for their experiments and to identify potential research focus areas. We structured the survey according to characteristics derived from potential use cases and research topics within the sense-plan-act paradigm.
Through an extensive investigation of 17 testbeds, we have evaluated 56 characteristics and have made the results of this analysis available on our webpage. We invited the testbed creators to assist in the initial process of gathering information and updating the content of this webpage. This collaborative approach ensures that the survey maintains its relevance and remains up to date with the latest developments.
The ongoing maintenance will allow researchers to access the most recent information. In addition, this paper can serve as a guide for those interested in creating a new testbed. The characteristics and overview of the testbeds presented in this survey can help identify potential gaps and areas for improvement.
One ongoing challenge that we identified with small-scale testbeds is the enhancement of their ability to accurately map to realworld conditions, ensuring that experiments conducted are as realistic and applicable as possible.
Overall, this paper provides a resource for researchers and developers in the fields of connected and automated vehicles and robot swarms, enabling them to make informed decisions when selecting or replicating a testbed and supporting the advancement of testbed technologies by identifying research gaps.”
Project Authors

Armin Mokhtarian is currently working as a Research Associate & PhD Candidate at RWTH Aachen University, Germany.

Patrick Scheffe is a Research Associate at Lehrstuhl Informatik 11 – Embedded Software, Germany.

Maximilian Kloock is working as a Team Manager Advanced Battery Management System Technologies at FEV Europe, Germany.

Simon Schäfer is a Visiting Researcher at Faculty of Engineering, University of Alberta, Canada.

Heeseung Bang is currently a Postdoctoral Associate at Cornell University, USA.

Viet-Anh Le is a Visiting Graduate Student at Cornell University, USA.

Sangeet Ulhas is a PhD candidate at Ira A. Fulton Schools of Engineering at Arizona State University, USA.

Johannes Betz is a Assistant Professor at Technische Universität München, Germany.

Sean Wilson is a Senior Research Engineer at Georgia Institute of Technology, USA.

Spring Berman is an Associate Professor at Arizona State University, USA.

Liam Paull is an Associate Professor at Université de Montréal, Canada and he is also the Chief Education Officer at Duckietown, USA.

Amanda Prorok is an associate professor at University of Cambridge, UK.

Bassam Alrifaee is a Professor at Bundeswehr University Munich, Germany.
Learn more
Duckietown is a platform for creating and disseminating robotics and AI learning experiences.
It is modular, customizable and state-of-the-art, and designed to teach, learn, and do research. From exploring the fundamentals of computer science and automation to pushing the boundaries of knowledge, Duckietown evolves with the skills of the user.
















































 - Duckietown")
 - Duckietown")
 - Duckietown")
 - Duckietown")
 - Duckietown")
 - Duckietown")
