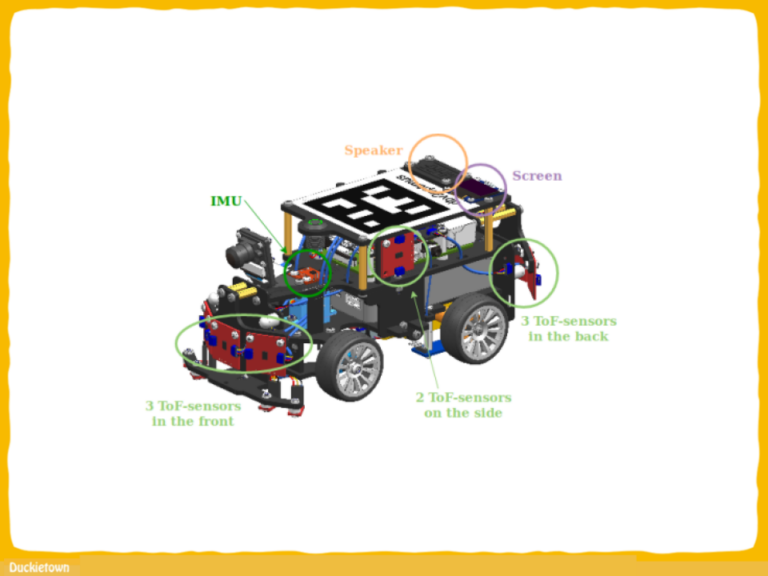
The new planning capailities of Duckiebots enable autonomous navigation building on pre-existing functionalities, such as “lane following”, “intersection detection and identification”, and “intersection navigation” (we are operating in a scenario with only one agent on the map, so coordination and obstacle avoidance are not central to this progect).
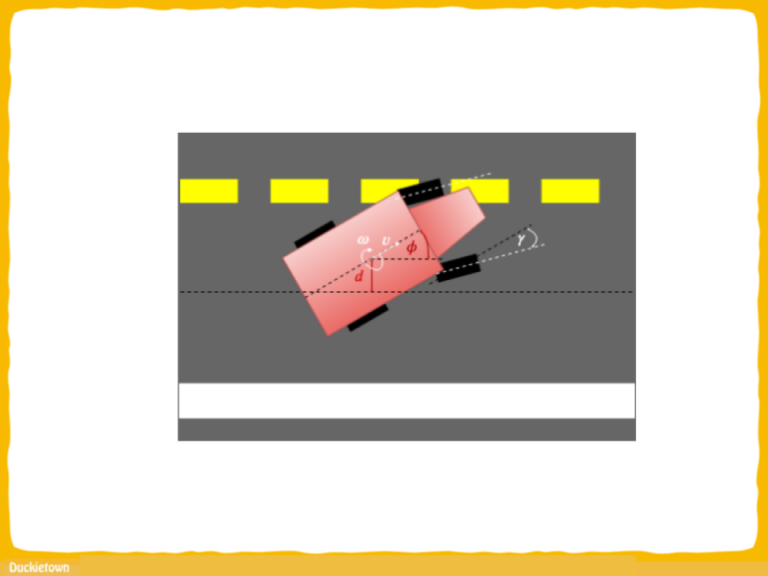
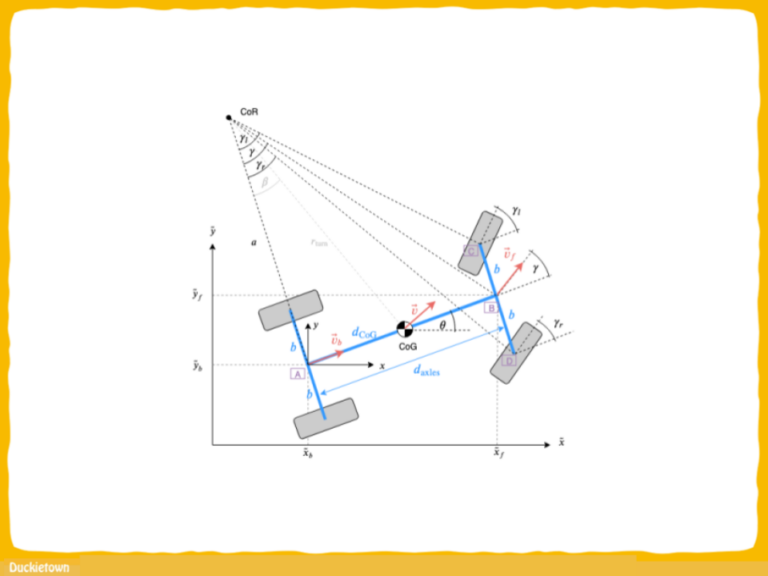
Lane following in Duckietown is mainly vision-based, and as such suffers from the typical challenges of vision in robotics: motion blur, occlusions, sensitivity to environmental lighting conditions and “slow” sampling.
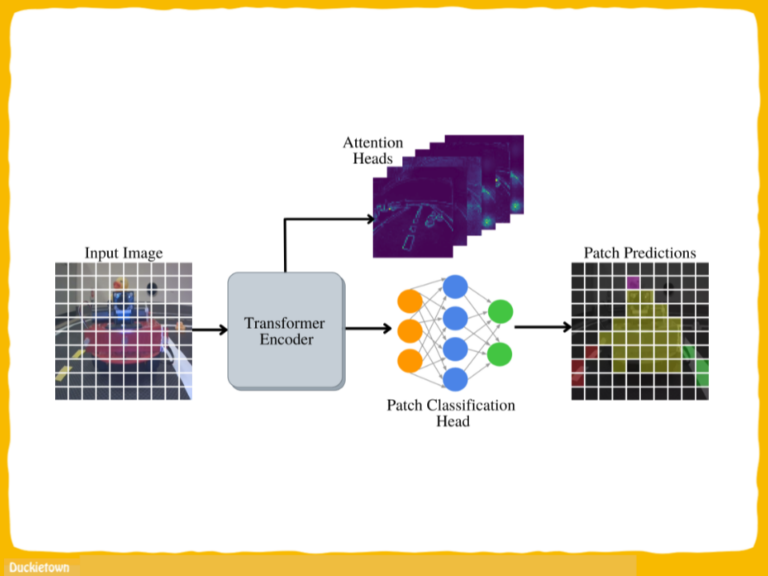
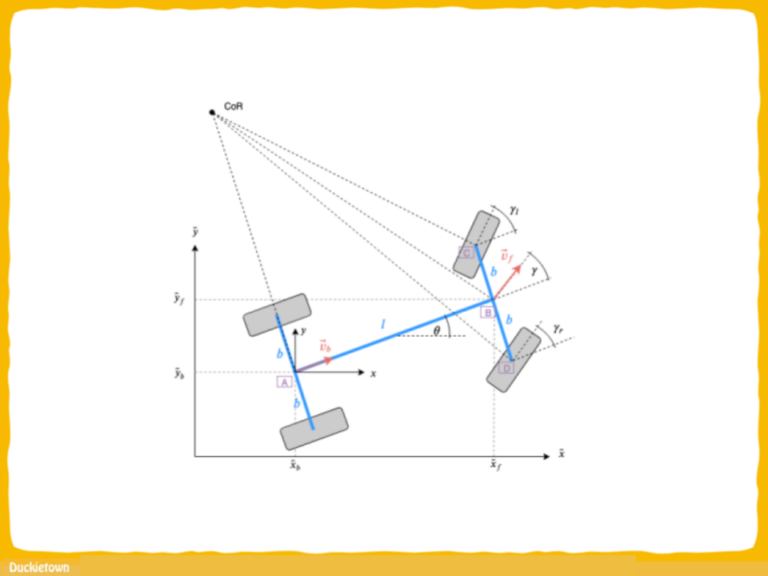
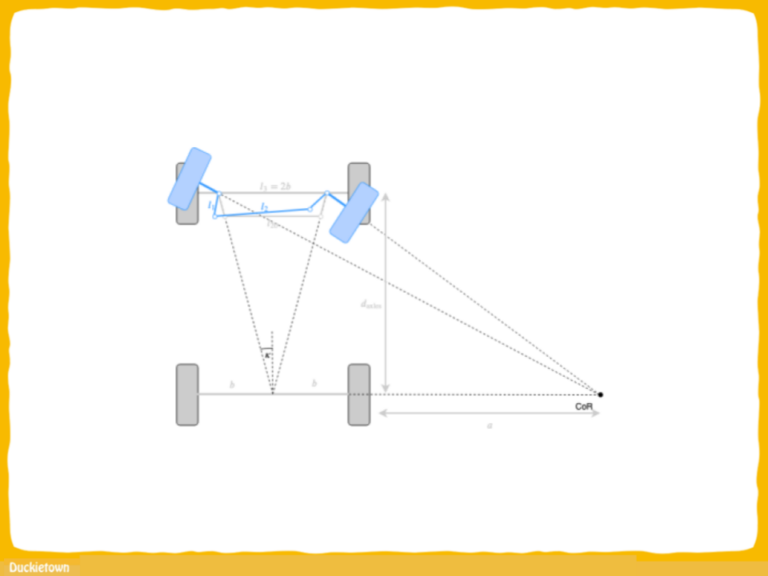
Intersection detection in Duckietown relies on the identification of the red lines on the road layer. Identification of the type of intersection, and relative location of the Duckiebot with respect to it, is instead achieved through the detection and interpretation of fiducial markers, appropriately specified and located on the map. In the case of Duckietown, April Tags (ATs) are used. Each AT, in addition to providing the necessary information regarding the type of intersection (3- or 4-way) and the position of the Duckiebot with respect to the intersection, is mapped to a unique ID in the Duckietown traffic sign database.
These traffic signs IDs can be used to unamiguosly define the graph of the city roads. Based on this, and leveraging the lane following pipeline state estimator, it is possible to estimate the location (with tile accuracy) of the Duckiebot with respect to a global map reference frame, hence providing the agent sufficient information to know when to stop.
After stopping at an intersection, detecting and identifying it, Duckiebots are ready to choose which direction to go next. This is where the Dijkstra planning algorithm comes into play. After the planner communicates the desired turn to take, the Duckiebot drives through the intersection, before switchng back to lane following behavior after completing the crossing. In Duckietown, we refer to the combined operation of these states as “indefinite navigation”.
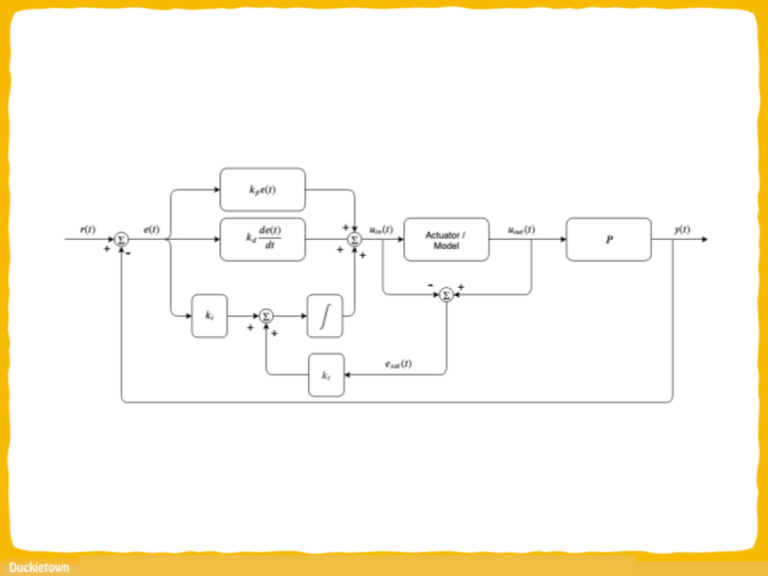
Switching between different “states” of the robot mind (lane following, intersection detection and identification, intersection navigation, and then back to lane following) requires the careful design and implementation of a “finite state machine” which, triggered by specific events, allows for the Duckiebot to transition between these states.
Integrating a new package within the existing indefinite navigation framework can cause inconsistencies and undefined behaviors, including unreliable AT detection, lane following difficulties, and inconsistent intersection navigation.
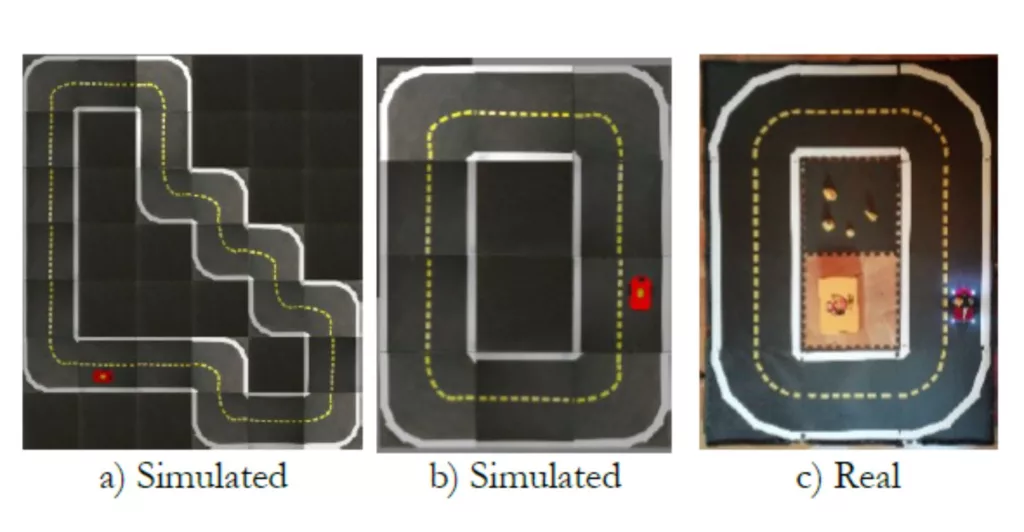
Performance evaluation of the GOTO-1 project involved testing three implementations with ten trials each, revealing variability in success rates.