The urban driving league uses the Duckietown platform and presents several challenges, each of increasing complexity.
The goal in each challenge is to develop a robotic agent for driving Duckiebots “well”. Baseline implementations are provided to test different approaches. There are no constraints on how your agents are designed.
Each challenge adds a layer of complexity: intersections, other vehicles, pedestrians, etc. You can check out the existing challenges on the Duckietown challenges server.
AI-DO 2021 features four challenges: lane following (LF), lane following with intersections (LFI), lane following with vehicles (LFV) and lane following with vehicles and intersections, multi-body, with full information (LFVI-multi-full).
All challenges have a simulation and hardware component ( ,
, ), except for
), except for LFVI-multi-full, which is simulation () only.
The first phase (until Nov. 7) is a practice one. Results do not count towards leaderboards.
The second phase (Nov. 8-30) is the live competition and results count towards official leaderboards.
Selected submissions (that perform well enough in simulation) will be evaluated on hardware in Autolabs. The submissions scoring best in Autolabs will access the finals.
During the finals (Dec. 1-8) one additional submission is possible for each finalist, per challenge.
Winners (top 3) of the resulting leaderboard will be declared AI-DO 2021 winter champions and celebrated live during NeurIPS 2021. We require champions to submit a short video (2 mins) introducing themselves and describing their submission.
Winners are invited to join (not mandatory) the NeurIPS event, on December 10th, 2021, starting at 11.25 GMT (Zoom link will follow).
 | Practice: Nov. 1-7 |
| Competition: Nov. 8-30 |
 | Finals: Dec. 1 – 8 |
 | Winners: Dec. 10 |
| Practice: unlimited non-competing submissions |
| Competition: best in sim are evaluated on hardware in Autolabs |
| Finals: one additional submission for Autolabs |
| Winners: 2 mins video submission description for NeurIPS 2021 event. |
Lane following 

Lane following with intersections

Lane following with vehicles

Lane following with vehicles and intersections (stateful)









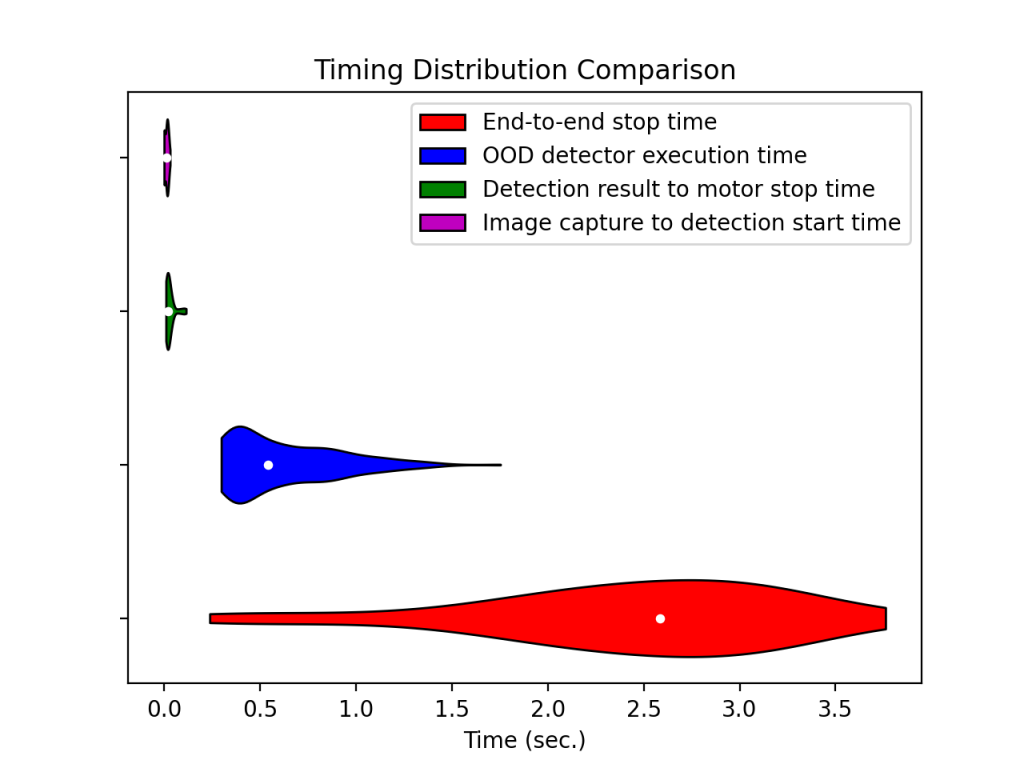
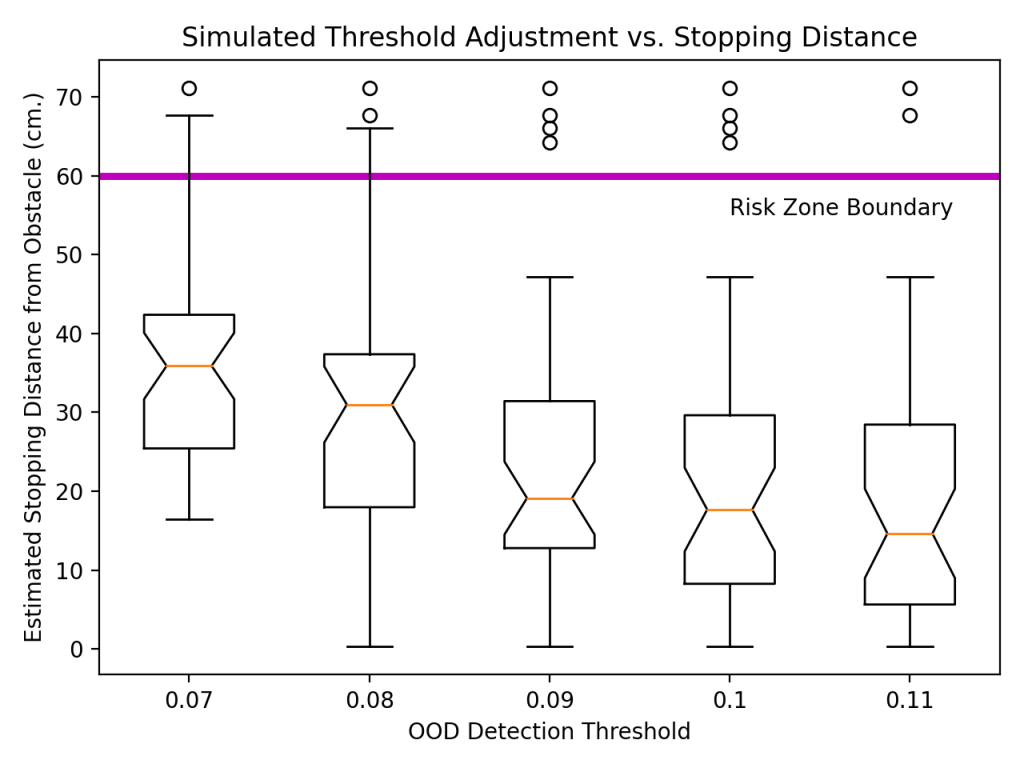












 - Duckietown")
 - Duckietown")